4. Modelos avanzados de BD
4. Modelos avanzados de BD
Las bases de datos o sistemas gestores de bases de datos han sido uno de los elementos de la informática más útiles hasta la fecha. La tecnología experimentó un gran crecimiento debido al uso masivo.
El modelo de bases de datos más utilizado ha sido el modelo relacional puesto que con él se puede resolver prácticamente la mayoría de los problemas que se plantean. No obstante, las nuevas necesidades han motivado el diseño y desarrollo de nuevos sistemas gestores de bases de datos que puedan lidiar con todo tipo de información y por ello han aparecido en el mercado las bases de datos deductivas, temporales, geográficas, distribuidas, etc.
4.1 Bases de Datos deductivas.
Las bases de datos deductivas surgieron ya hace bastante tiempo (década de los 80) y el objetivo es integrar junto con una base de datos relacional mecanismos de reglas y hecho mediante los cuales poder inferir o deducir nueva información.
Este tipo de bases de datos intenta aportar el conocimiento existente sobre inteligencia artificial y la lógica al de las bases de datos.
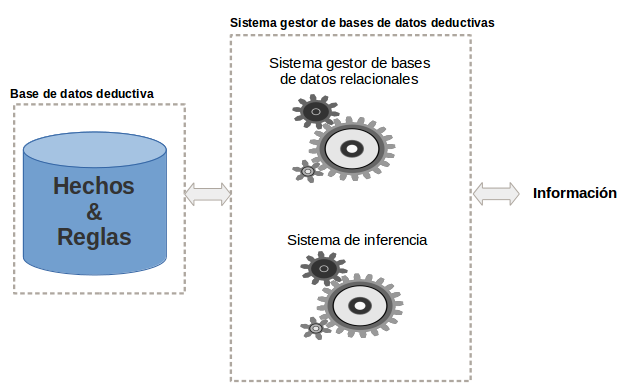
Figura 4.1. Esquema de una base de datos deductiva.
Como se puede observar en la figura anterior estas bases de datos contienen hechos y reglas:
-
Los hechos representan el conocimiento explícito que está registrado en la base de datos relacional. Se expresarían de una manera parecida a las relaciones en una base de datos relacional.
-
Las reglas representan el conocimiento implícito. Mediante estas reglas por y por medio de la inferencia se podrá generar nueva información. Las reglas no pueden compararse con las vistas de una base de datos relacional. Las reglas son un mecanismo más complicado puesto que pueden contener recursividad entre ellas.
Las bases de datos deductivas no han sido muy usadas a nivel comercial, sí se han estado utilizando en entornos de investigación y algunos campos de ciencias aplicadas. No obstante, es posible que con la evolución de la informática y la complejidad de ciertos sistemas se puedan utilizar en el futuro.
4.2 Bases de datos temporales.
Las bases de datos relacionales o tradicionales no pueden considerarse bases de datos históricas puesto que no se puede navegar a través del tiempo con ellas y disponer del estado de los datos en un momento determinado.
Las bases de datos tradicionales almacenan datos históricos si insertamos información en ellas y nunca la modificamos ni borramos (solo añadimos) o bien contienen los datos actuales (cuando borramos, actualizamos o insertamos algún dato el estado de la base de datos en el momento anterior se pierde).
Recuerda.
En una base de datos temporal se puede conocer el estado de los datos en un momento determinado.
Las bases de datos temporales surgen por la necesidad de almacenar los datos a través del tiempo. Por ejemplo si queremos crear un sistema informático para gestionar las reservas de una compañía aérea o para gestionar las cotizaciones bursátiles de un mercado, la monitorización meteorológica de una cuenca hídrica, etc, una solución sería utilizar una base de datos temporal para almacenar y gestionar la información generada.
Recuerda.
En una base de datos temporal se almacenan datos históricos y datos actuales.
Las bases de datos temporales almacenan además de la información dos datos bitemporales que son:
-
El tiempo de transacción que es el tiempo en el que se ha incluido el hecho en la base de datos (se almacena el tiempo de transacción inicial y el final).
-
El tiempo de validez que es el tiempo en el que el dato es válido en el mundo real (se almacena el tiempo de validez inicial y el final).
Debido a que se almacenan estos dos datos bitemporales, este tipo de base de datos se denominan también bases de datos de restauración o de rollback ya que nos permite restablecer la base de datos en un momento temporal pasado cualquiera recuperando el estado de la misma. También estas bases de datos se denominan bases de datos de snapshot porque además de los datos almacenan información sobre el tiempo de transacción y el tiempo de validez.
Las bases de datos actuales (Oracle, SQL Server, Informix, MySQL, Sybase, etc) no tienen capacidad para realizar esta gestión de forma simultánea del tiempo de transacción y del tiempo de validez.
Claves primarias.
Las claves primarias de las bases de datos temporales tienen que añadir ahora referencias temporales para poder ser operativas.
4.2.1 TimeDB

Figura 4.2. TimeConsult, una compañía puntera en bases de datos temporales.
TimeDB de TimeConsult es una base de datos bitemporal basada en SQL que tiene un lenguaje de consulta, un lenguaje de manipulación de datos, un lenguaje de definición de datos y restricciones de integridad.
Fue desarrollada por Andreas Steiner y la primera versión se escribió en SICStus Prolog. La versión 2 se ha escrito en Java por su carácter multiplataforma, utiliza JDBC, ofrece un API y tiene mayor funcionalidad que las versiones anteriores.
TimeDB utiliza un lenguaje denominado ATSQL2, el cual ha sido propuesto para ser un estandar por los comités ISO y ANSI.
Internamente como backed TimeDB (el frontend) utiliza una base de datos Oracle o IBM Cloudscape y las sentencias ATSQL2 se traducen en sentencias SQL92 las cuales son ejecutadas por el backend (Oracle o IBM Cloudscape). Esta arquitectura permite a TimeDB no depender de ningún gestor de bases de datos, aumenta su portabilidad y mejora su fiabilidad y eficiencia al utilizar gestores de bases de datos comercialmente reconocidos.
Actualmente la última versión en el mercado es la 2.2, compatible con Java 1.4 y testada con Oracle 10g e IBM Cloudscape 10.
4.3 Bases de datos geográficas
Una base de datos geográfica también se denomina SIG (Sistema de Información Geográfica) o GIS (Geographic Information System). Un SIG es un sistema informático construido para gestionar, manipular, almacenar, analizar y presentar datos geográficos o espaciales.

Figura 4.3. Ficha personal de Robert Tomlinson.
En un SIG se pueden representar ciudades, carreteras, ríos, provincias y todo tipo de accidentes geográficos. El objetivo de un SIG es recoger datos de múltiples fuentes que pueden estar en distintos formatos e integrarlos en un único sistema.
Una vez integrados todos esos datos se pueden detectar problemas, patrones o información que con otro formato de presentación como textos, tablas, etc no eran tan patentes. Esta característica se denomina Ventaja Geográfica.
Como puede deducirse, el visualizar los datos sobre un mapa presenta muchas más ventajas que con otros formatos y permite analizar y comprender datos sobre el mundo y la actividad humana.
Los datos que se pueden integrar en un SIG pueden ser de todo tipo. Imaginemos que plasmamos en un SIG datos referentes a una epidemia. Esta información representada en un mapa puede ser de gran ayuda para las autoridades sanitarias y políticas para establecer planes de acción y tomar decisiones que con otro tipo de información serían más difíciles de tomar. Otra información que se puede integrar en un SIG sería el recorrido de un huracán, los diferentes cultivos de una zona, la distribución poblacional, etc.
Muchas veces multinacionales, antes de establecer tiendas o puntos de venta utilizan SIG en los que integran la población existente en diferentes zonas, la edad de la población, el nivel adquisitivo, competidores, las comunicaciones, etc. Una vez integrados todos estos datos, el sistema dice cuales son las localizaciones más rentables para establecer sus tiendas.
La ventaja geográfica.
Se denomina ventaja geográfica a la claridad con la que se ven ciertos datos, patrones o información dentro de un SIG que con otro formato no sería tan evidente.
Figura 4.4. Ejemplo de datos integrados en un SIG.
Actualmente utilizan SIG entre otros colectivos los siguientes:
-
Los militares. Lo utilizan para entender el terreno y tomar decisiones tales como desplegar tropas, utilizar un tipo de equipo u otro. Ver qué zonas son más seguras y cuáles no.
-
Los meteorólogos. Lo utilizan para entender fenómenos atmosféricos y hacer predicciones. También durante desastres naturales como inundaciones, huracanes, terremotos este tipo de sistemas son muy útiles para organizar la ayuda y evacuar a la gente.
-
En las telecomunicaciones. La telefonía móvil y otros servicios pueden ayudarse de SIG para dar la mejor cobertura y el mejor servicio a un colectivo de personas.
-
En el cuidado forestal. Permite determinar dónde hay que talar árboles, donde hay que sembrar otros, dónde hay que trabajar para evitar y prevenir incendios, etc.
-
En los negocios. Como ya se ha explicado antes, los datos en un SIG pueden dar una ventaja competitiva a las compañías y les puede permitir ampliar o mejorar negocios con garantías.
-
Las smart cities. Muchas ciudades se han apuntado a este nuevo concepto. El objetivo es ofrecer a los ciudadanos un servicio de acuerdo a sus necesidades, maximizar la utilización de infraestructuras, flexibilizar la oferta de servicios, mejorar la eficiencia, conocer mejor el coste de los servicios, etc. En otras palabras, ofrecer una calidad de vida superior a los ciudadanos.
4.4 Bases de datos distribuidas.
Un sistema de bases de datos distribuido permite a cualquier aplicación acceder a datos de una base de datos ya sea local o remota.
Generalmente hay tres formas en las cuales se puede implementar un sistema de bases de datos distribuido:
-
Sistema de base de datos distribuido homogéneo.
-
Sistema de base de datos distribuido heterogéneo.
-
Sistema de base de datos distribuido cliente/servidor.
4.4.1 Sistema de base de datos distribuido homogéneo.
Un sistema de base de datos distribuido homogéneo es un sistema en el que existen una serie de bases de datos con el software del mismo fabricante y generalmente con distinta información en cada una de ellas. Al ser todas las bases de datos del mismo fabricante la comunicación entre las distintas bases de datos suele ser fluida (generalmente el acceso de una base de datos a otra es nativo).
En ocasiones, aunque es el mismo fabricante de software para todas las bases de datos la versión puede ser diferente. Eso no es óbice para que se considere una base de datos distribuida homogénea.
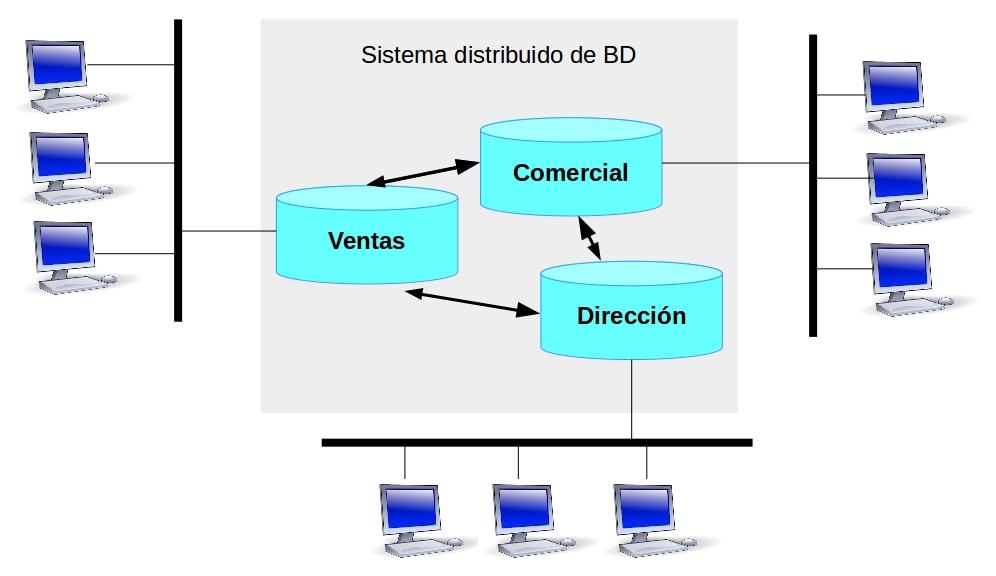
Figura 4.5. Sistema de bases de datos distribuido homogéneo.
En principio los usuarios acceden a la base de datos de forma transparente. Los usuarios no saben dónde reside la información, es el propio sistema el que se encarga de localizar y recuperar los datos de la base de datos correspondiente.
Por ejemplo los usuarios que accedan a la bases de datos de dirección pueden consultar cual es el producto más vendido el último trimestre. Los datos de ventas están en otra base de datos pero el usuario en principio no tiene porqué saberlo, es el propio sistema el que se encarga de acceder a dichos datos.
4.4.2 Sistema de base de datos distribuido heterogéneo.
Un sistema de base de datos distribuido heterogéneo es un sistema en el que existen una serie de bases de datos con el software de distinto fabricante, quizás no en todas las bases de datos pero sí en alguna de ellas.

Figura 4.6. Sistema de bases de datos distribuido heterogéneo.
Al ser productos de distinto fabricante el problema reside en la comunicación entre bases de datos. Esa comunicación tiene que ser fluida. Muchas veces se necesita un driver o software que haga de pasarela entre un sistema y otro.
En ocasiones se puede utilizar sistemas de conectividad genérica entre bases de datos como puede ser el protocolo ODBC u OLE DB.
4.4.3 Sistema de base de datos distribuido Cliente/servidor.
En un sistema de bases de datos cliente/servidor cuando un cliente se conecta para obtener un dato lo puede hacer directa o indirectamente:
-
Una conexión directa sucede cuando el cliente se conecta a su servidor y este tiene los datos almacenados que se le solicitan.
-
Una conexión indirecta sucede cuando en el servidor del cliente no están almacenados los datos solicitados y el servidor a su vez tiene que conectarse como cliente a otro servidor para poder obtenerlos.
Como se puede observar, dentro de los nodos (servidores de base de datos) cada nodo puede hacer unas veces como servidor y otras como cliente.
4.5 Bases de datos analíticas (OLAP).
OLAP es el acrónimo de Online Analytical Processing, la cual es una tecnología para gestionar grandes bases de datos de negocios en las cuales se va a realizar business intelligence o inteligencia de negocio. Básicamente se van a extraer y visualizar los datos desde diferentes puntos de vista.
Para poner un ejemplo imaginemos que un almacén quiere mostrar el número de productos de ferretería que ha vendido en el mes de Febrero en una zona concreta (Castilla y León). Además quiere hacer una comparativa con los mismos productos vendidos en esa misma zona pero en el mes de Octubre.
Este tipo de consultas se pueden realizar con una base de datos relacional pero no son tan fáciles de plantear puesto que las bases de datos tradicionales son bidimensionales (filas y columnas, las filas tienen los datos y las columnas los campos).
4.5.1 Data mining.
Data mining como se ha dicho agrega datos para identificar patrones y establecer relaciones no identificadas entre los mismos.
Las técnicas de data mining se utilizan en muchas áreas de investigación como marketing, genética, matemáticas, negocios, cibernética, etc. Existe también el término web mining el cual intenta sacar partido a la gran cantidad de información que puede extraer un sitio web sobre patrones de comportamiento de los usuarios. Esto se utiliza en CRM (Customer Relationship Management). Por ejemplo muchos de los sitios como Amazon llevan haciendo esto desde hace muchos años, por eso cuando accedes al sitio web siempre muestran productos de tu afinidad y tus gustos.
Data mining puede descubrir patrones sobre eventos (cuando ocurre algo es probable que ocurra esto otro), también se pueden buscar patrones entre eventos (si fumas tienes más probabilidad de desarrollar cáncer). También se pueden descubrir patrones que lleven a realizar predicciones sobre el futuro (este área se llama análisis predictivo).
4.6 Bases de datos de columnas.
Por regla general la mayoría de los gestores de bases de datos (gestores relacionales) almacenan la información en columnas. Pues bien, los gestores de bases de datos orientados a columnas los almacenan en columnas. Muchas veces cuando almacenamos los datos en columnas en vez de en filas ciertos sistemas como los CRM (Customer Relationship Management), los catálogos, los data warehouses, business intelligence, etc, obtienen ventajas de ello y los hacen más eficientes.
El tener los datos almacenados en columnas al ser todos los datos del mismo tipo permite optimizar las operaciones sobre ellos. La desventaja que tienen estos tipos de bases de datos es que si la base de datos va a soportar muchas escrituras el rendimiento se ve penalizado puesto que tiene que escribir en muchas columnas, por lo tanto estas bases de datos son eficientes cuando el número de lecturas van a ser muy superior al número de escrituras.

Figura 4.7. Almacenamiento de datos en bases de datos relacionales y columnares.
Como se puede ver en la imagen anterior, el indicador de fila (ROWID) le va a servir al sistema para poder enlazar los datos de cada fila dentro del almacenamiento por columnas.
En el caso que consultemos en una base de datos los coches de un determinado rango de precios o consultemos un modelo concreto, el sistema de base de datos orientado a columnas será más eficiente mientras que si lo que consultamos es una serie de modelos concretos con un rango de precios el sistema tradicional le aventajará en eficiencia.
Cuando se van a consultar o combinar pocas columnas de los datos de una tabla, generalmente las bases de datos orientadas a columnas suelen ser más eficientes que una base de datos tradicional. También son más eficientes cuando se modifican todos los datos de una columna de una tabla. Por el contrario, las bases de datos tradicionales son más eficientes cuando queremos recuperar todos los datos de una fila concreta, o queremos modificar varios campos de una fila concreta o el número de columnas o el tamaño de una fila es pequeño.
Algunos sistemas aprovechan el que las columnas tengan el mismo tipo de datos para comprimirlas y así maximizar el espacio necesario. El éxito de la compresión muchas veces depende de la cardinalidad (número de distintos valores) de la columna. A menor cardinalidad mayor será la compresión.
4.7 Bases de datos documentales.
Una base de datos documental u orientada a documentos al contrario que una base de datos tradicional lo que almacena y recupera son documentos. Este tipo de bases de datos se denomina también bases de datos NoSQL. En este tipo de base de datos no existen las tablas ni las relaciones sino los documentos los cuales son un conjunto grande de datos.
Dependiendo de la implementación, la funcionalidad y las características de la base de datos pueden variar. En muchas ocasiones la única necesidad que se tiene es almacenar el título, autor, ISBN, la fecha y el propio documento escaneado en PDF o incluso procesado con un OCR (Object Character Recognition). Para este tipo de operaciones no hace falta utilizar una base de datos documental puesto que con una base de datos tradicional solucionamos el problema. Nuestra base de datos tendría una tabla con 5 campos siendo el último campo el que contiene el documento de tipo BLOB o de texto con mucha longitud.
Generalmente las bases de datos documentales almacenan documentos el XML, HTML, JSON, YAML, BSON, Microsoft Office u otro formato en los cuales puede la información estar dividida en secciones (cabecera, pie, capítulo, autor, etc). Los documentos no tienen que tener una estructura similar como ocurre en una base de datos relacional sino que cada documento será diferente.
Este tipo de base de datos pueden acceder y gestionar la información de una manera más inteligente de lo que lo haría una base de datos relacional o SQL. Las bases de datos documentales modernas aunque tienen un número reducido de columnas las cuales son atributos del documento, también son capaces de extraer metadatos de los documentos y se puede trabajar con los mismos. Se puede recuperar documentos basándonos en el contenido que tienen. Las bases de datos ofrecen una serie de APIs para realizar consultas.
Dependiendo del tipo de base de datos y sus características, las consultas y sus resultados pueden tener distinto rendimiento.
4.8 Bases de datos XML.
Una base de datos XML permite almacenar datos en formato XML. Como cualquier base de datos permite consultar dichos datos y transformarlos en el formato deseado. Generalmente estas bases de datos se asocian a base de datos documentales.
El uso del XML como formato para el intercambio de información hace necesario la utilización de este tipo de bases de datos. De esa manera, el almacenamiento, consulta y procesamiento se hacen más eficientes dado que los gestores no tienen que realizar conversiones sino que pueden interpretar los datos XML en sí mismos.
En estos entornos nativos XML ya no se utilizan lenguajes como SQL sino otros adaptados a este modelo como pueden ser XQuery y XPath.
Podríamos clasificar las bases de datos XML en dos grandes grupos:
-
Las bases de datos XML nativas. Estas bases de datos aunque no tengan que tener necesariamente la información almacenada en ficheros XML. Su modelo interno se basa en XML y su unidad de almacenamiento es el documento XML (para las bases de datos relacionales es la fila).
-
Bases de datos que permiten el uso de XML (no nativas). Estas bases de datos suelen ser bases de datos tradicionales como las bases de datos relacionales y permiten XML como entrada y pueden generar XML como salida. La base de datos se encarga de procesar el XML sin necesidad de utilizar ningún middleware.

Figura 4.8. Algunas bases de datos XML.
Algunas bases de datos XML son:
-
MarkLogic. Con licencia propietaria.
-
BaseX. Con licencia BSD.
-
eXistdb. Con licencia LGPL.
-
sedna. Con licencia Apache.
![]()
Figura 4.9. Logo de eXistdb.
eXistdb fué creada en el año 2000 por Wolfgang Meier y en 2006 en InfoWorld fué considerada la mejor base de datos XML. Se utiliza de forma masiva en la arquitectura de aplicaciones web XRX.
eXistdb es una base de datos XML de código abierto que está catalogada como una base de datos no SQL. Es una base de datos nativa XML y proporciona soporte para JSON, HTML y documentos binarios. Se puede trabajar con XQuery y con XSLT con esta base de datos además de con sus herramientas de consulta y lenguajes de programación.
4.8.1 XQuery
XQuery es para XML lo que SQL es para una bases de datos tradicional. Un ejemplo de consulta en XQuery sería el siguiente:
for $x in doc(«coches.xml»)/concesionario/coches
where $x/precio>25000
order by $x/modelo
return <li>{data($x/modelo)}</li>
Como se puede apreciar es muy similar a SQL en su semántica pero podemos ver características de los lenguajes de programación como cláusulas for, return, let, etc. Las expresiones que se utilizan en XQuery se denominan sentencias FLWOR (FOR, LET, WHERE, ORDER BY y RETURN).
XQuery 1.0 es una Recomendación del W3C desde el 23 de enero de 2007.
XQuery es compatible con otros estándares de la W3C como XML, XSLT, XPath o Namespaces.
Como se puede observar, XQuery es un lenguaje de consulta y extracción de información y atributos de archivos XML. Anteriormente se mostró un ejemplo de consulta que en lenguaje normal sería el siguiente:
Selecciona todos aquellos modelos de coches que estén en el concesionario cuyo precio sea mayor a 25.000 euros y que están registrados en el archivo coches.xml.
XQuery 1.0 y XPath 2.0 comparten las mismas funciones, operadores y el mismo modelo de datos.
XPath se utiliza para navegar a través de elementos y atributos en un documento XML.
XPath es un estándar del W3C y XQuery y XPointer se basan en las expresiones XPath.
¿Para qué utilizar XQuery?
-
Para transformar datos de XML a XHTML.
-
Para realizar búsquedas en documentos XML a través de la web.
-
Para realizar informes con datos de estadísticas, etc.
-
Para ser utilizado por un servicio web para mostrar información.
-
Procesar ficheros XML.
Para entender mejor el el concepto, veamos cómo se integra XQuery en HTML para realizar consultas en documentos XML y cuales son los resultados obtenidos. En primer lugar tenemos el siguiente documento HTML el cual, como se puede observar tiene código XQuery:
<html>
<body>
<h1>Concesionarios del Sur: Modelos de coches</h1>
<ul>
{
for $x in doc(«coches.xml»)/concesionario/coches
where $x/precio>25000
order by $x/modelo
return <li>{data($x/modelo)}</li>
}
</ul>
</body>
</html>
Al procesar el intérprete de XQuery la expresión anterior generará un resultado HTML que se fusiona con el ya existente y el resultado será el siguiente:
<html>
<body>
<h1>Concesionarios del Sur: Modelos de coches</h1>
<ul>
<li>Ferrari Testa Rosa</li>
<li>Lamborghini Diablo</li>
<li>Mercedes SLK</li>
<li>Range Rover Vogue</li>
</ul>
</body>
</html>
4.9 Bases de Datos incrustadas (embedded).
Actualmente las aplicaciones sobre todo las aplicaciones móviles (apps) necesitan tener un sistema gestor de base de datos que se encuentre muy integrado con el software de la aplicación y por obvios motivos este gestor no tiene que tener mantenimiento o ser mínimo.
Dado que muchas veces el sistema tiene unas restricciones importantes de memoria y capacidad de procesamiento estas bases de datos tienen que ser eficientes y ofrecer características de los motores de bases de datos tradicionales.
Estos nuevos gestores de bases de datos tienen que ofrecer algunas de las características de los servidores de bases de datos tradicionales pero adecuados a las circunstancias de cada dispositivo. Por ejemplo deberían ofrecer:
-
Arquitectura cliente/servidor. Muchas de estos gestores funcionan como un sistema cliente/servidor como puede ser Oracle o MySQL.
-
Diferentes modos de almacenamiento (en disco, en memoria o una combinación de ambos). En el caso que se opte por el almacenamiento en memoria (para que sea más rápida), una vez que termina el programa vuelcan el contenido de las tablas a disco para preservar la persistencia.
-
Ofrecer un lenguaje de consulta estándar como el SQL (además de alguno propietario).
-
Modelos de base de datos relacionales, orientados a objeto, etc. Muchas de estas bases de datos van a ser accedidas a través de lenguajes orientados a objetos como Java, Objetive C y demás y por lo tanto ofrecer un SGBD OO es una ventaja fundamental.
-
Diferentes tipos de producto para diferentes mercados, diferentes dispositivos, etc.
Para una mayor eficiencia estos gestores de bases de datos no están siempre ejecutándose, no se inicia un servicio en la máquina sino que se distribuyen como librerías con las que enlazará nuestro código en el caso que queramos ejecutarla. El servicio corre siempre dentro de un proceso.
¿Cuando utilizar este tipo de bases de datos?
Cuando no se va a utilizar la funcionalidad al 100% de un gestor de bases de datos tradicional.
Cuando no se pueda instalar un gestor de bases de datos.
Cuando el objetivo es almacenar datos a pequeña escala.
Cuando la portabilidad sea un requisito fundamental.
Cuando haya escased de memoria.
4.9.1 SQLite
![]()
Figura 4.10. Logo de SQLite.
SQLite es una librería software que implementa un motor de bases de datos transaccional SQL. Su ventaja es que no necesita configurarse ni tampoco residir en un servidor al ser simplemente una librería. Su ventaja es que es el motor de base de datos más utilizado a nivel mundial.
SQLite es capaz de almacenar en un solo fichero una base de datos con sus tablas, índices, triggers y vistas.
El código fuente de SQLite es de dominio público (escrito en ANSI-C) y hace que SQLite sea la base de datos por excelencia utilizada en smartphones, tablet, reproductores MP3 y otros dispositivos electrónicos. Su secreto radica en que hace un uso muy eficiente de la memoria, del espacio en disco, es muy fiable y no necesita ningún tipo de mantenimiento ni persona que la administre.
SQLite está implementado en más sitios de los que te imaginas, desde pequeñas aplicaciones y proyectos hasta proyectos de gran envergadura.
Si estás pensando en crear un sitio web pequeño o mediano, seguramente SQLite es una opción a tener en cuenta para almacenar la información debido a que no requiere ningún tipo de configuración y la información se almacena en ficheros normales y corrientes.
Muchas aplicaciones han dejado de utilizar XML, JSON, CSV u otros formatos para almacenar información en ficheros y actualmente utilizan una base de datos SQLite porque permite acceder a los datos como con una base de datos pero sin el trabajo de administración y mantenimiento que una base de datos tradicional conlleva.
Aunque SQLite no tiene la potencia de un servidor de bases de datos tradicional, muchas grandes empresas lo utilizan para testear o desarrollar prototipos. SQLite en esos casos es muy útil al no requerir instalación, fácil de utilizar, eficiente y rápido. Obviamente SQLite no reemplaza a Oracle pero puede ser una alternativa más potente que fopen() que utiliza ficheros CSV, JSON o XML.
SQLite es multiplataforma.
Con SQLite puedes copiar una base de datos de un sistema de 32 bits a uno de 64 y viceversa y funcionará. De igual modo puedes intercambiar ficheros entre sistemas con diferentes arquitecturas.
Dependiendo de la plataforma y de la optimización del compilador, SQLite que generalmente ocupa un espacio menor a 500KB podría llegar a tener 300KB o menos. Esto unido a los pocos recursos que consume hace que sea la base de datos más utilizada en dispositivos pequeños como smartphones, tablet, MP3 y otros. Además, aun con poca memoria, SQLite funciona de una manera eficiente.
Si el código es abierto ¿Quién mantiene y mejora este producto?
Aunque el código es software libre y hay una serie de desarrolladores que trabajan a tiempo completo en SQLite para mejorarlo y ampliar su funcionalidad sin que pierda retrocompatibilidad, si quieres soporte profesional tienes que pagarlo. También están abiertos a donaciones, por supuesto. De esa manera se financian y pueden ofrecer un buen producto de una forma competitiva.
4.10 Nuevas tendencias en Bases de datos.
Actualmente la evolución tecnológica es vertiginosa sobre todo por la irrupción de nuevos dispositivos hardware, nuevas tendencias, nuevas necesidades, etc. La industria necesita ajustar las herramientas a esas nuevas necesidades con la finalidad de poder atender a los requerimientos de los clientes.
En el campo de las bases de datos, las bases de datos relacionales han dominado dicho paradigma y dado que es un modelo excelente, robusto, basado en fórmulas matemáticas, fácilmente representado por algoritmos, etc, el modelo relacional está vigente en el día de hoy. Edgar Codd puede estar contento que en nuestros días su modelo sea la base de muchos de los actuales sistemas de bases de datos comerciales y no comerciales.
En la actualidad con la irrupción de nuevas necesidades ha irrumpido el paradigma NoSQL el cual no rompe con el modelo relacional sino que sirve de comodín para resolver problemas de una forma más eficiente que las bases de datos tradicionales. En este tema hemos repasado algunas de esas bases de datos como las bases de datos columnares, bases de datos documentales, bases de datos XML, etc.
Es cierto que este tema se queda corto puesto que nos hubiese gustado tratar otras bases de datos y conceptos importantes en la actualidad como las bases de datos orientadas a objetos, bases de datos activas, almacenes clave-valor, Big Data o Data Warehouse. No obstante, tratar todos estos conceptos en más o menos profundidad nos llevaría un libro solamente por lo tanto ten en cuenta que el mundo de las bases de datos está en continua evolución y que hay que seguirlo de cerca porque es un mundo apasionante.
Big Data.
Big data es un término que describe cómo un volumen muy grande de datos (estructurados, semiestructurados y no estructurados) se pueden gestionar para ser analizados y extraer información de ellos.
Big Data se caracteriza por las tres uves:
Volumen. Hay un volumen extremo de datos, podemos hablar de petabytes o exabytes de información. Obviamente gestionar este volumen no es tarea fácil.
Variedad. Hay una gran variedad de información. La información es muy diversa y los tipos de datos también.
Velocidad. La información hay que procesarla de forma muy rápida con el problema del volumen que conlleva.