5. Análisis detallado de la distribución de BD
5. Análisis detallado de la distribución de BD
Cuando nacieron las bases de datos en la época de los 70 y 80 no se pensaba de momento en información que estuviese distribuida en varios lugares. El pensamiento estaba en centralizar la información en un solo punto estando gestionado por un SGBD o Sistema Gestor de Bases de Datos. Con la aparición de las redes y la revolución de Internet este enfoque cambia. La información no tiene que estar fija en un sitio sino que puede distribuirse en varias localizaciones para hacer los sistemas más eficientes.
A continuación se estudiará en profundidad algunos de los conceptos de los sistemas de bases de datos distribuidas.
5.1 Formas y principios de la distribución.
Actualmente muchos sistemas o tecnologías son sistemas distribuidos como pueden ser las aplicaciones web, el comercio electrónico, etc. ¿El porqué de esto? Porque en nuestra era de Internet la máxima «divide y vencerás» ha prevalecido sobre otras estrategias. Muchas veces es más eficiente dividir el problema y realizar esas subpartes más sencillas de manera más rápida que centralizar todo el procesamiento en un solo lugar con las desventajas que ello conlleva. Los sistemas de bases de datos distribuidas (SBDD) siguen esa filosofía que los hace eficientes y rápidos.
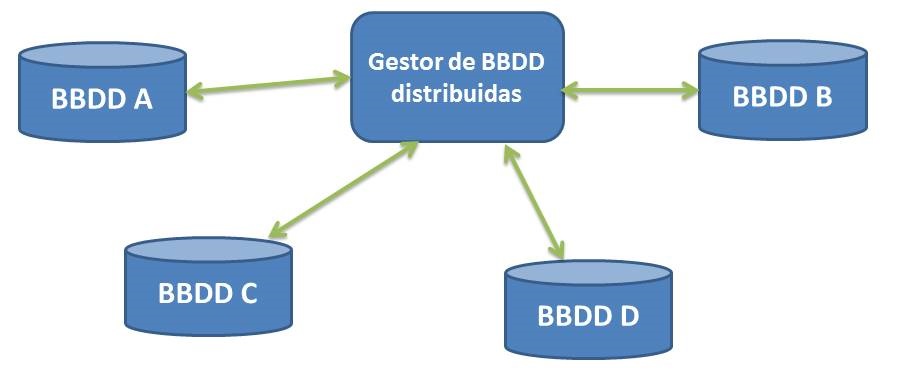
Figura 5.1. Esquema de un sistema de bases de datos distribuidas
Como ya se ha comentado, en un sistema de bases de datos distribuidas hay como mínimo dos bases de datos generalmente interconectadas por una red (no importa la distancia entre los equipos donde residen las bases de datos, puede ser una red local, Internet, etc). También existe un sistema llamado gestor de bases de datos distribuidas. Ese sistema gestor es el responsable de la distribución y el que hace que al usuario le parezca que esta interactuando con una única base de datos cuando realmente lo esta haciendo con un grupo de ellas.
Muchas veces esta distribución de datos en nodos acarrea problemas que con un sistema centralizado no ocurren. Imaginemos que los datos están muchas veces duplicados en varios nodos. En ese caso el gestor tiene que decidir a qué nodo accede a por un dato y en el caso que se actualice o se inserten nuevos datos deberá tener en cuenta cuáles nodos se verán afectados. Además las transacciones distribuidas se complican puesto que hay que sincronizar y coordinar peticiones y respuestas entre varios nodos.
Entre las ventajas que tiene un sistema de base de datos distribuido están los siguientes:
-
Mejora de la fiabilidad y disponibilidad. Al mantener los datos muchas veces replicados en varias localizaciones se tiene la ventaja de poder tener el sistema operativo aun cuando se caiga uno de los nodos. El sistema no cae por completo con lo cual se aumenta la fiabilidad y está disponible durante más tiempo mejorando su disponibilidad. En un sistema centralizado la caída del nodo único implica una pérdida del servicio.
-
Mejora en la escalabilidad. En caso de necesidad se pueden ir añadiendo nuevos nodos al sistema con una repercusión mínima sobre el mismo.
-
Aumenta la transparencia. Es posible reubicar datos, reubicar nodos, replicar datos, etc sin que los usuarios tengan constancia de ello. Además todas estas operaciones se pueden realizar haciendo que el acceso siga siendo eficiente y efectivo.
-
Mejora del rendimiento. Al repartir la carga de trabajo entre diferentes nodos el sistema gana en rendimiento puesto que no concentra el trabajo en un punto único.
Citemos ahora algunas de sus desventajas:
-
El catálogo es más complejo dado que su gestión se complica. Además hay que mantener réplicas del mismo lo que implica una sincronización entre las mismas.
-
Control de la concurrencia. Aunque se utilicen bloqueos para evitar la concurrencia, el control del mismo al tener muchos nodos en funcionamiento complica su gestión.
-
Las actualizaciones hay que replicarlas en todos los nodos implicados. En el caso que un nodo no esté disponible el sistema tiene que tener constancia de ello y tenerlo en cuenta. Muchas veces estos sistemas funcionan con un sistema de copia primaria y luego una serie de copias secundarias que se irán actualizando posteriormente.
5.2 Arquitectura ANSI/X3/SPARC.
ANSI/X3/SPARC es acrónimo de Standard Planning And Requirements Committee of the American National Standards Institute on computers and Information Processing. Este organismo a finales de los años setenta estableció el estándar de organización de las bases de datos que hoy en día se sigue utilizando.
La idea es proponer una arquitectura general que sirva para describir la organización del sistema. Se pensó en una arquitectura basada en tres niveles, además se describieron las interacciones entre los mismos y los elementos de los que estaban compuestos.
Los tres niveles son los siguientes:
-
Nivel Interno o físico. En este nivel físico se describe cómo estarán almacenados los datos en la base de datos. Para ello se apoya en un modelo físico de datos.
-
Nivel Conceptual. En este nivel se describe la estructura «conceptual» que tendrá la base de datos sin tener en cuenta los aspectos físicos de almacenamiento que se contemplan en la capa anterior. La distribución de la información en este nivel se fija en entidades, relaciones y atributos.
-
Nivel Externo o de usuario. En este nivel se hace hincapié en que cada usuario tiene una visión de la base de datos distinta. Existen distintas vistas o esquemas externos de usuario.
El objetivo de esta estructuración a tres niveles es independizar los programas de la base de datos física. De esa manera el desarrollo de aplicaciones es más rápido y normalizado.
Hay que decir que los SGBD actuales respetan estas capas pero internamente no al 100%. Muchos de ellos intercambian elementos de un nivel en otro y en ocasiones no existe una independencia marcada entre el nivel externo o de usuario y el nivel conceptual. Obviamente hay que tener en cuenta que el rendimiento es muy importante y estar transformando datos entre capas no es la mejor manera de aumentarlo.
Este tipo de arquitectura en tres niveles tiene su sentido cuando se desea tener una independencia de datos tal, que se pueda modificar una capa sin tener que modificar las capas contiguas. Por lo tanto los dos tipos de independencia de datos que se pueden definir son los siguientes:
-
Independencia lógica. Implica el poder cambiar el esquema conceptual sin tener que modificar las vistas de los usuarios pues siguen siendo válidas. Generalmente este tipo de cambios consisten en ampliación o reducción de la base de datos (añadiendo o disminuyendo su número de entidades).
-
Independencia física. Implica el poder cambiar el esquema físico de almacenamiento sin tener que modificar el esquema conceptual. Cualquier consulta tanto de selección como de borrado o inserción seguirá siendo válida.

Figura 5.2. Niveles y proceso de correspondencia en la arquitectura ANSI/X3/SPARC
Transformar las peticiones y la información de un nivel a otro se llama proceso de correspondencia. Como se puede observar dos niveles de correspondencia no son muy efectivos ni eficientes por lo tanto los sistemas gestores de bases de datos comerciales no utilizan este sistema en la actualidad.
5.3 Transacciones distribuidas.
Las transacciones distribuidas son equivalentes a las transacciones normales dentro de una base de datos pero con la particularidad que dicha transacción va a abarcar dos o más bases de datos.
Muchas veces, el usuario no conoce si la transacción es distribuida o no. Es el propio gestor de base de datos el que la trata como tal, al tener constancia que el ámbito de la misma traspasa lo que sería una transacción local.
En ocasiones, las transacciones distribuidas abarcan más de un servidor de base de datos. En ese caso, dicha transacción debe ejecutarse de forma coordinada entre los mismos.
Generalmente en ese tipo de situaciones existe un servidor que se erige como coordinador de la transacción. El coordinador de la transacción es el responsable de gestionar las notificaciones, notificar los errores que se puedan producir o indicar de forma final que la transacción es correcta y se ha llevado a cabo.
Normalmente las transacciones distribuidas son similares a las transacciones locales. El proceso de una distribución distribuida se lleva en dos fases:
-
La primera fase se denomina fase de preparación. En esta fase el coordinador de transacciones envía comandos de preparación a todos los gestores (o responsables de gestionar los datos) implicados. Cada gestor implicado realiza las operaciones pertinentes y notifica al coordinador si la preparación ha tenido éxito o no.
-
La segunda fase se denomina fase de confirmación. En esta fase, el coordinador de transacciones tiene todas las notificaciones de los gestores implicados y si son correctas (todas) envía nuevos comandos de confirmación de las operaciones. Los gestores de los recursos completan la transacción y notifican que la confirmación se ha realizado de forma correcta. En el caso que el coordinador de la transacción haya recibido toda las confirmaciones con éxito, envía una notificación a la aplicación indicando que todo se ha ejecutado correctamente. En caso contrario notificará del error a la aplicación y envía un nuevo comando para indicar a los gestores de los recursos que reviertan la situación.
Veamos todo esto con un ejemplo más visual:
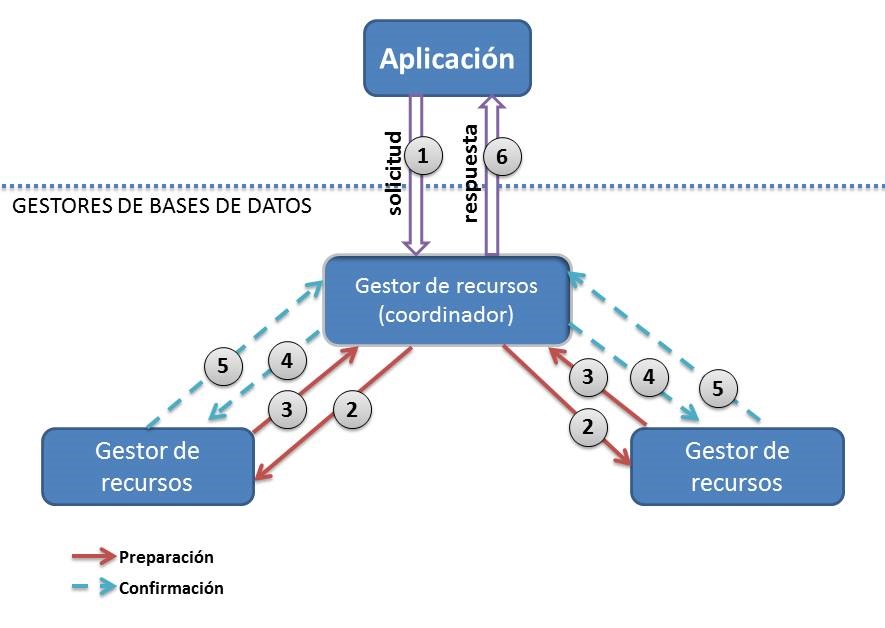
Figura 5.3. Esquema de una transacción distribuida
Solicitud de transacción.
-
Paso 1: La aplicación solicita realizar una transacción. El sistema estima que es una transacción distribuida porque afecta a dos o más bases de datos. El sistema se prepara para una transacción distribuida y un gestor de recursos se erige como coordinador de la transacción.
Fase de preparación.
-
Paso 2: El coordinador de transacciones envía comandos de preparación a todos los gestores de recursos.
-
Paso 3: Cada gestor implicado realiza las operaciones pertinentes y notifica al coordinador si la preparación ha tenido éxito o no.
Fase de Confirmación.
-
Paso 4: El coordinador de transacciones tiene todas las notificaciones de los gestores implicados y si son correctas (todas) envía nuevos comandos de confirmación de las operaciones.
-
Paso 5: Los gestores de los recursos completan la transacción y notifican que la confirmación se ha realizado de forma correcta.
Respuesta a la aplicación.
-
Paso 6: El coordinador de la transacción notifica a la aplicación si la transacción se ha realizado con éxito o no.
5.4 Mecanismos de distribución de datos.
En las bases de datos distribuidas existen dos formas diferente de descentralizar el control de la misma o distribuir la información. La distribución cliente/servidor y la distribución peer-to-peer también llamada distribución completa. Ambos son totalmente diferentes. En una estructura cliente/servidor la importancia de cada nodo es diferente (tienen distintos roles) mientras que en una distribución peer-to-peer todos los nodos tienen la misma importancia (no existen diferentes roles).
5.4.1 Distribución cliente/servidor
La arquitectura cliente/servidor divide la lógica del sistema en dos partes diferenciadas. Por un lado la parte servidora que tendrá una serie de atribuciones y por otra la parte cliente.
El sistema gestor de bases de datos distribuidas deberá decidir cómo reparte las atribuciones del sistema entre ambas entidades. En ocasiones los servidores son responsables de almacenar los datos mientras que los clientes se encargan de gestionar las peticiones de los clientes y almacenar copias locales de datos. Clientes y servidores se comunican mediante sentencias SQL y mensajes petición/resultado.
Este tipo de arquitectura muchas veces soluciona problemas de complejidad tanto del sistema como de la distribución de datos.
Existen varias formas de atacar el problema bajo una perspectiva cliente/servidor. La primera es tener varios clientes y un solo servidor. Esta solución no es compleja de implementar y la correcta definición de los roles y atribuciones es fundamental a la hora de repartir la carga de trabajo. El objetivo es no tener un servidor colapsado por las peticiones o un servidor ocioso y múltiples clientes saturados.
Hay que tener cuidado al diseñar este sistema de no caer en replicar un sistema clásico centralizado. Si delegamos todas o la mayoría de las funciones en el servidor lo que estamos creando es un sistema antiguo (centralizado) con apariencia moderna (distribuida).
Otra posibilidad es tener varios clientes y varios servidores. En esta ocasión la complejidad se acrecienta dado que hay que decidir entre otras cosas qué clientes acceden a qué servidores, cómo gestionar este sistema con múltiples servidores, cómo se van a sincronizar entre ellos, etc.
5.4.2 Distribución peer-to-peer
Esta distribución de funciones surge de un paradigma mucho más moderno como es el peer-to-peer. En este sistema cada nodo tiene igual importancia que otro nodo, con lo cual dicho sistema funciona de igual manera con dos nodos que con decenas o cientos de ellos.
Para implementar este sistema hay que crear capas de abstracción como vimos en la arquitectura ANSI/X3/SPARC. El acceso a los datos por parte de las aplicaciones debe ser transparente e independiente de donde se encuentren localizados los datos.