¿Cómo se gestiona una CPU o Unidad de Control de Proceso (UCP)?
1. Procesos y flujos
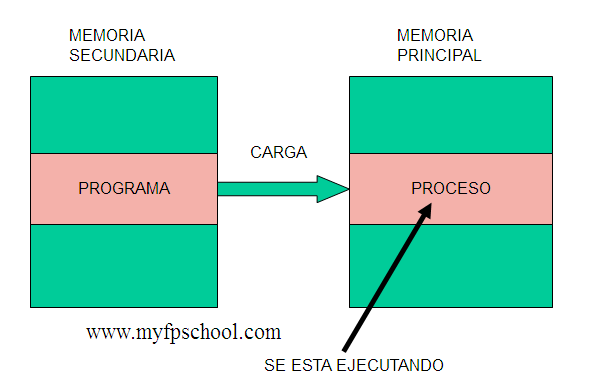
Carga de un proceso a memoria
Hay que diferenciar entre proceso y programa. Un programa reside en memoria secundaria generalmente y son una serie de órdenes que sirven para ejecutar una tarea con un fin determinado. Un proceso al contrario que un programa se ubica en memoria principal, luego se está ejecutando. Son las mismas órdenes pero al situarse en memoria principal, la CPU puede ejecutarlas mientras que en memoria secundaria no es posible su ejecución.
Por lo tanto el proceso de carga es el proceso por el cual el programa pasa a situarse en memoria principal y desde ese momento se le denomina proceso.
La CPU es la encargada de ejecutar, sincronizar y asignar los recursos de un sistema a los diferentes procesos que se estén ejecutando en el mismo. Esos recursos se asignan en un orden determinado atendiendo a unas prioridades dadas.
En memoria puede haber muchos procesos ejecutándose a la vez (de forma concurrente), por lo tanto van a ir demandando una serie de recursos (memoria, CPU, etc.), y será la CPU como ya se ha dicho la encargada de suministrar dichos recursos de forma ordenada.
El bloque de control de proceso.
Igual que nosotros para gestionar nuestros contactos telefónicos tenemos una lista con una serie de campos para cada uno de nuestros contactos (nombre, teléfono, dirección, etc.), la CPU tiene su propia lista. Para identificar cada proceso, la CPU utiliza una estructura de datos o registro que identifica de forma unívoca cada proceso y que le va a permitir controlar la ejecución del mismo. Esta estructura se denomina bloque de control de proceso y tendrá como mínimo los siguientes datos:
* Estado actual del proceso
* Identificador del proceso (PID)
* Prioridad del proceso
* Ubicación en memoria
* Recursos utilizados
¿Por qué hay que crear procesos?
La respuesta es muy sencilla, si se quiere ejecutar aplicaciones en un sistema o comandos es necesario crear un proceso por cada vez que se quiera ejecutar una aplicación o un comando. Imaginemos que queremos imprimir algún documento, entonces necesitaremos crear un nuevo proceso. Imaginemos que queremos proporcionar una serie de servicios en una red como por ejemplo, un servidor web, un servidor de impresión, etc. En ese caso deberemos tener activo un proceso como mínimo por cada servicio que se quiera ofrecer.
Algunos de estos procesos se pueden crear al iniciar el sistema, otros por parte del usuario, otros por clonación los cuales son copias casi exactas (casi porque se diferencian en que cada uno tiene un identificador diferente – PID o process identifier diferente).
En sistemas Linux y Unix, los procesos se estructuran de forma jerárquica. Existen procesos padre, hijos… La estructura de procesos es como un árbol genealógico. En este árbol genealógico existe un proceso el cual es el primero y ocupa la raíz del árbol de procesos. Este proceso es especial y se denomina init. Se caracteriza por tener identificador igual a uno (PID=1).
2. Estado de los procesos
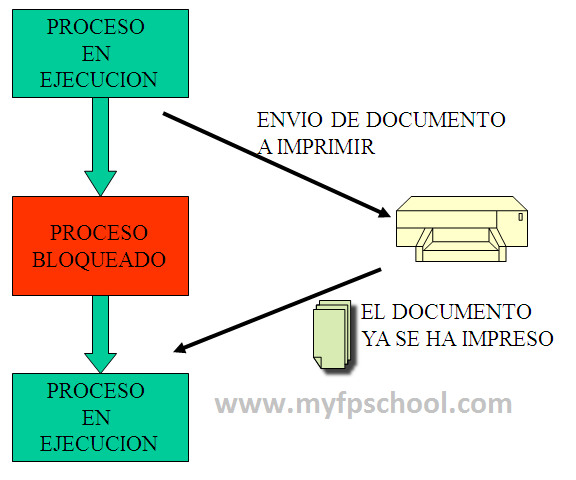
Estado del proceso al imprimir un documento
Los procesos no están siempre ejecutándose en un sistema. Muchas veces los procesos están bloqueados hasta que se dan las circunstancias necesarias para volver a ejecutarse. Imaginemos que mandamos un trabajo a imprimir, el proceso de impresión comienza a imprimir las primeras páginas del documento y a mitad del mismo la impresora se queda sin papel. El proceso se bloquea (se queda en estado bloqueado) hasta que la impresora le envía la señal de que esta lista para volver a imprimir (en ese caso volverá a estar en estado activo).
El sistema operativo es el encargado de controlar el estado de los diferentes procesos y controlar también la transición de un estado a otro.
Por lo tanto hemos visto que un proceso puede encontrarse en un estado u otro dependiendo de la situación en que se encuentra en cuanto a la utilización de los recursos hardware del equipo.
Estados de un proceso
Los estados en los que se puede encontrar un proceso son los siguientes:
- En ejecución. Un proceso esta en ejecución cuando el procesador está ejecutando las instrucciones del mismo. En ese momento, el SSOO le ha concedido el uso de CPU.
- En espera, activo o preparado. Un proceso esta activo o preparado cuando esta esperando a que se le conceda el uso de los recursos del sistema y por lo tanto poder seguir ejecutando las instrucciones de las que se compone.
- Bloqueado. Cuando un proceso no puede acceder a un recurso el sistema operativo lo puede poner en estado bloqueado. Un proceso puede estar en estado bloqueado por muchas razones, por ejemplo, si hay dos procesos que necesitan acceder al mismo archivo, el sistema tiene que poner uno en estado bloqueado mientras que el otro proceso accede al fichero. Cuando el primer proceso termina de acceder al recurso (el fichero) y lo libera, entonces el sistema operativo desbloquea el segundo proceso y permite continuar su ejecución accediendo al fichero que previamente ha sido liberado. De esa manera el sistema impide que se den situaciones no deseadas al acceder dos procesos al mismo recurso.
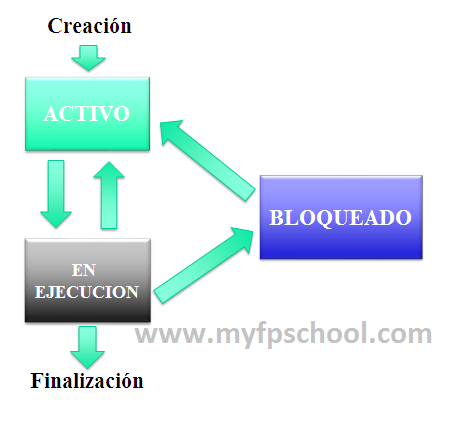
Transición de estados de un proceso
Como puede verse en la imagen, los procesos van pasando de un estado a otro, en primer lugar cuando se crean, el sistema los marca como activos (eso quiere decir que están disponibles para ser ejecutados), cuando el sistema lo estima oportuno, le asigna recursos como la CPU, entrada/salida u otros y su estado pasa a estar en ejecución. Los distintos procesos se van a alternando en el uso de la CPU y los demás recursos del sistema.
En un momento dado, el proceso termina su ejecución de forma voluntaria o bien por error y en ese momento deberá devolver al sistema todos los recursos que le habían sido asignados como la memoria, los archivos, tablas en el kernel, etc.
Hay que tener en cuenta que algunos procesos nunca terminan. Estos procesos se denominan demonios/daemons o también servicios. Un ejemplo de un proceso de este tipo es un servidor web (siempre estará activo).
Algunos procesos no mueren (demonios o daemons): httpd, sshd, …
Identificación de los procesos
.
Cualquier proceso en el sistema tiene que estar debidamente identificado. Al igual que las personas tienen un DNI que las identifica de forma inequívoca, el proceso tiene su PID (Process ID) que lo identifica frente a otros procesos. Este PID es un numero asignado por el sistema operativo que servirá para identificar el proceso, lanzarlo a ejecución, detenerlo, cancelarlo, reanudarlo, etc.
Transición entre estados
.
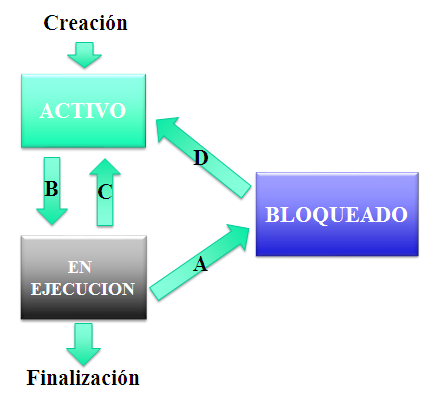
Transición entre estados
Como hemos visto, un programa va cambiando de estado, cada cambio de estado se denomina transición y en la imagen se representan varias transiciones entre estados de un mismo proceso. Pasemos a ver una a una estas transiciones:
- Transición A. El programa en ejecución necesita algún elemento señal, dato, etc, para poder seguir ejecutándose.
- Transición B. El proceso ha utilizado el tiempo asignado por la UCP (procesador) para su ejecución y tiene que dejar paso al siguiente proceso.
- Transición C. El proceso que esta preparado (activo) pasa a ejecución
- Transición D. El proceso pasa de estar bloqueado a estar preparado. El proceso ya ha recibido la señal, dato u orden que estaba esperando para pasar al estado de preparado o activo. Luego pasaría a ejecución.
Cambio de contexto.
Cuando un proceso pasa de un estado a otro, como por ejemplo el paso de un proceso en espera a ejecución, se esta produciendo en dicho paso un cambio de contexto.
Recuerda: Cambio de contexto es el paso de un proceso de un estado a otro.
Siempre que un proceso sale de la CPU hay que guardar el estado para el siguiente turno de ejecución
El estado tendrá que incluir el valor de los registros de la CPU, que una vez el proceso vuelve a estar en ejecución, dichos valores son restituidos.
El bloque de control de procesos guardará el estado en que se encuentra el proceso.
3. Las señales (signals).
Las señales se les envían a los procesos y sirven para avisar al proceso de algo concreto. Se le puede enviar una señal para comunicarle algo desde otro proceso , para controlarlo desde el terminal (suspenderlo, terminarlo, etc.), desde el kernel cuando comete una infracción (ej.: acceso ilegal a memoria), etc.
Estas señales pueden ser capturadas por los procesos o ignoradas. Si se quiere capturar la señal habrá que programar un handler o manejador de la señal, en caso contrario, se ejecutará la acción por defecto.
Las señales se representan mediante un número entero (del 1 al 31).
Algunos ejemplos son los siguientes:
HUP (1), QUIT (3), KILL (9), SEGV (11), etc.
Importante: Las señales KILL y STOP no pueden ser capturadas.
4. Comandos para el control de procesos
- ps. Este comando muestra un listado de los procesos que se están ejecutando en ese mismo instante en el sistema.
- top. Este comando muestran en tiempo real el listado de procesos que se están ejecutando en el sistema.
- kill. Este comando permite enviar señales a los procesos que se estén ejecutando en el sistema. Si se le quiere enviar una señal a un proceso para que termine basta con ejecutar «kill -9 idproceso», siendo idproceso el PID o número de proceso asignado por el sistema.
A continuación se mostrarán utilidades de estos comandos:
1. Los siguientes comandos listan los procesos que se están ejecutando en el sistema ordenados por % cpu. En dichos comandos se eliminan aquellos que usan 0.0 de CPU con sed (sed ‘/^ 0.0 /d):
ps -e -o pcpu,cpu,nice,state,cputime,args –sort pcpu | sed ‘/^ 0.0 /d’
2 Los siguientes comandos listan los procesos del sistema ordenados por uso de memoria (en KB):
ps -e -orss=,args= | sort -b -k1,1n | pr -TW$COLUMNS
5. Prioridad de los procesos
Linux asigna el tiempo de CPU a cada proceso tomando en cuenta la prioridad del mismo. Esta prioridad viene representada con un número y a menor valor de este número, mayor prioridad se tiene de obtener la CPU.
La CPU se asigna dinámicamente, esto quiere decir que las prioridades pueden cambiar y son tenidas en cuenta a cada momento. En ocasiones se puede considerar el otorgar una prioridad negativa (si por ejemplo se ejecuta una Entrada/Salida).
La prioridad la asigna el administrador o el propio sistema y dependiendo de esta prioridad va a depender que un proceso se ejecute en más o menos tiempo.
Generalmente, los programas más importantes o los que más se ejecutan tienen una prioridad mayor que aquellos programas que no se ejecuten muy frecuentemente o que no sean importantes para el sistema operativo.
6. Planificación de procesos
La planificación permite al sistema organizar los procesos que deben ejecutarse y los estados que deben ir adoptando.
Para planificar un sistema existen unos algoritmos de planificación. Estos algoritmos deciden en cada momento que proceso ha de ejecutarse y por qué.
Algunas características de estos algoritmos son:
- La imparcialidad.
- La equidad.
- La eficiencia.
- El tiempo de respuesta.
- El rendimiento.
Carga de un proceso.
La carga de un proceso la realiza el cargador y es una tarea del propio sistema operativo.
El ejemplo más sencillo de entender es cuando se hace doble clic sobre el icono de un programa. En ese momento, el cargador mueve el código del programa a la memoria principal para que el proceso se ejecute. El programa se convierte en proceso.
El cargador realiza una serie de funciones las cuales se enumeran a continuación:
- Crea el BCP (bloque de control del proceso) y le asigna un identificador de proceso, se asigna una prioridad base y los recursos que ha pedido menos la CPU.
- Inserta el proceso en la tabla de procesos del sistema.
- Carga el proceso en memoria virtual.
- Una vez que tiene todos los recursos asignados. Al proceso se le pone el campo de estado del proceso del BCP en preparado y se añade en la cola de procesos listos para hacer uso de la CPU.
La planificación
El planificador es un proceso del sistema operativo y es el encargado de elegir que proceso será el siguiente en ser atendido por la CPU. La elección se realiza mediante las prioridades que ya hemos visto.
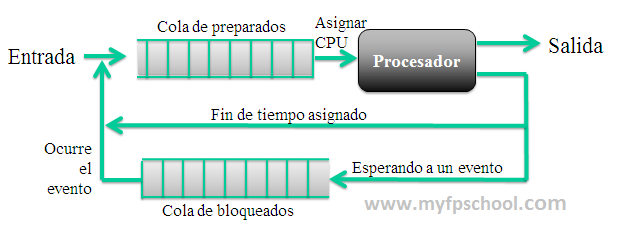
Modelo de cola de procesos
Los sistemas utilizan colas para planificar la ejecución de los procesos. Cuando un proceso entra al sistema va directamente a una cola de preparados. Cada proceso tiene una prioridad y es entonces el sistema el que elige el proceso al que va a asignar la CPU. Una vez asignada la CPU pueden ocurrir tres cosas, que el proceso termine por ejecutarse del todo, que se agote el tiempo de CPU asignado al proceso (en ese caso vuelve a la cola de preparados) o que el proceso quede bloqueado a la espera de un evento (en ese caso irá a la cola de bloqueados). Si un proceso esta en la cola de bloqueados a la espera de un evento y este ocurre, automáticamente pasa a la cola de preparados.
7. Características de los sistemas operativos
Actualmente, cualquier sistema operativo puede gestionar varias tareas al mismo tiempo (es un sistema multiproceso). Hace mucho tiempo, los sistemas operativos solamente podían ejecutar una tarea a la vez (eran sistemas monoproceso).
Como la mayoría de los ordenadores actuales tienen un único procesador, esto implica que si se están realizando varias tareas a la vez, es necesario compartir el tiempo de trabajo de la CPU.
El tiempo compartido en un sistema consiste en dividir el tiempo de ejecución en porciones llamadas quantums e ir asignando cada uno de esos intervalos a cada proceso que está en ejecución.
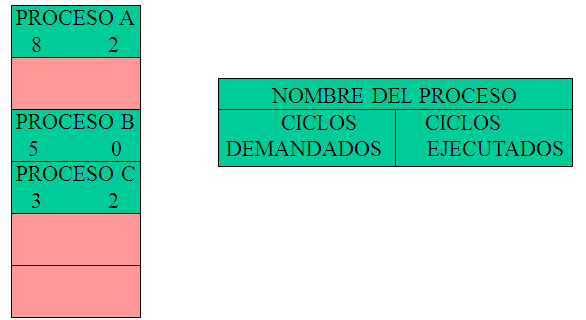 En la tabla de procesos se van almacenando los ciclos de CPU que se han ido asignando a los diferentes procesos.
En la tabla de procesos se van almacenando los ciclos de CPU que se han ido asignando a los diferentes procesos.
Esta información es muy importante para poder planificar los procesos y ser lo mas justo posible con cada uno de los procesos.
El numero total de procesos en el sistema queda determinado por el numero de entradas ocupadas en la tabla de procesos.
En la tabla de procesos se representa toda la información acerca de cada uno de los procesos que se están ejecutando en el sistema. En el momento que vuelvan a ejecutarse, se partirá del mismo punto en que se quedo la ejecución.
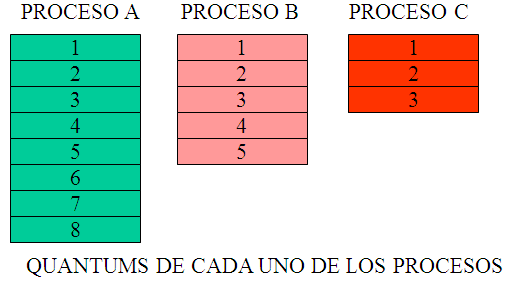
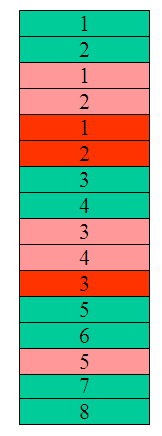
Orden de ejecución en la CPU
La CPU va ejecutando procesos con un criterio determinado. En este caso, los procesos se van ejecutando por orden de llegada y para que un proceso no acapare la CPU, se van asignando 2 quantums de tiempo a cada proceso hasta que se finalicen todos los procesos en ejecución.
Imaginemos que un proceso solicita una operación de E/S. En ese caso se pone en estado suspendido dicho proceso y se coloca en la cola del dispositivo de E/S que quiere utilizar.
Cuando ya ha satisfecho esta operación de E/S, se vuelve a poner en estado preparado y se coloca en la cola de preparados.
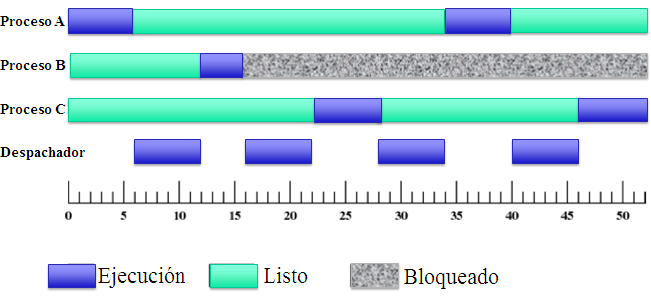
La ejecución de los procesos se representan mediante diagramas temporales. En el eje X se representa el tiempo mientras que en el eje Y se representan los procesos.
Durante la ejecución de los procesos existe uno que se llama despachador o dispatcher el cual es el responsable de realizar los cambios de contexto. Los cambios de contexto en un sistema no salen gratis, el sistema tarda un tiempo en guardar los registros de un proceso y volver a cargar los registros de otro, con lo cual, cuantos menos cambios de contexto en un sistema mejor.
8. El planificador
El sistema necesita conseguir un comportamiento adecuado y por lo tanto tiene que asignar los recursos de la manera más eficiente que se pueda. Concretamente es el planificador el que se encarga de asignar estos recursos.
En un sistema operativo hay tres tipos de planificadores que pueden coexistir:
- Planificador a largo plazo
- Planificador a medio plazo
- Planificador a corto plazo
En los ejemplos y futuros ejercicios que vamos a ver consideraremos que solo existe uno.
Como se ha explicado el encargado de decidir qué proceso pasará a ejecución de entre todos los procesos que estén en estado preparado es el planificador.
El planificador sigue las directrices de un algoritmo para elegir el siguiente proceso a ejecutar y el tiempo que se le va a asignar. Este algoritmo de planificación tiene que tener en cuenta aspectos como el rendimiento, el tiempo de espera, el tanto por ciento de uso del procesador, el tiempo de CPU asignado al dispatcher y a los procesos, el número de procesos ejecutados por unidad de tiempo, etc.
9. Sincronización de procesos
Lo más normal en un sistema es que los procesos se ejecuten de forma concurrente y accedan a los mismos recursos. Estos es un problema y el sistema operativo tiene que implementar mecanismos para evitar conflictos. Estos mecanismos se denominan sincronización. El objetivo de la sincronización es que dos o mas procesos concurrentes no puedan utilizar los mismos recursos en el mismo instante de tiempo. Por esta razón habrá bloqueados mientas que otros procesos están en ejecución.
10. Algoritmos de planificación
Como ya se ha comentado, es el planificador el encargado de decidir qué proceso tiene que ejecutarse, el planificador utiliza un algoritmo para hacer que el sistema de elección sea lo más justo posible, tenga la CPU ocupada con procesos de usuario el mayor tiempo posible, minimice el tiempo de respuesta (que no tarde mucho el sistema desde que llega el proceso hasta que comienza a ejecutarse, que no se monopolicen los recursos, etc.
El planificador tiene que tener en cuenta dos cuestiones:
- 1º Cual es el la forma o manera de decidir qué proceso se tiene que ejecutar (para ello se basa en un algoritmo).
- 2º Cuando se aplica esa forma de decidir (en qué momento).
Teniendo en cuenta esta segunda cuestión, podemos dividir los algoritmos de decisión en dos categorías:
- Algoritmos apropiativos.
- Algoritmos no apropiativos.
Algoritmos apropiativos y no apropiativos.
Algoritmo no apropiativo.
Este tipo de algoritmos cuando se le otorga la CPU a un proceso no se le retira hasta que acaba la concesión. La concesión puede terminar cuando finaliza de ejecutarse, solicita algún servicio del sistema o se bloquea por una operación de entrada/salida. También se le conoce a este tipo de algoritmos como multitarea cooperativa (cooperative multitasking). Una de las ventajas de estos algoritmos es que los trabajos con poca prioridad logran ejecutarse con mayor agilidad que en un algoritmo apropiativo, también son más predecibles pero por contra, puede pasar que un proceso largo haga esperar a los demás ralentizándolos de esta manera.
Algoritmo apropiativo.
Los algoritmos apropiativos pueden interrumpir la ejecución del proceso si le llega una demanda de un proceso nuevo con mayor prioridad. En cualquier momento el sistema puede «cambiar de idea» y revocar la concesión que había otorgado a un proceso. Esta revisión de prioridades siempre se produce cuando llega un nuevo proceso al sistema o se desbloquea un proceso. El objetivo de este tipo de algoritmos es priorizar los procesos más importantes relegando la ejecución de los menos prioritarios a otro momento en el que el sistema este más liberado. A este tipo de planificación se la llama planificación por torneo. El problema que tiene este tipo de algoritmos, es que cuando hay muchos procesos que llegan al sistema, se producen muchos cambios de contexto lo que implica que el dispatcher ocupe mucho tiempo de CPU bajando el rendimiento de la misma.
Algoritmo de rueda o Round Robin.
Este algoritmo asigna el mismo quantum o intervalo de tiempo de ejecución a cada uno de los procesos del sistema de forma rotatoria. El objetivo de este algoritmo es la equidad. Repartir el tiempo por igual entre todos los procesos de tal manera que el que pide más tiempo tardará más en ejecutarse.
La selección entre los procesos se hará por orden de llegada. Se comenzará a otorgar la CPU al primer proceso que llega hasta llegar al último.
Algoritmo FCFS (First Come First Serve – Primero que llega primero en salir).
Este algoritmo prima el orden de llegada de los distintos procesos, de tal manera que no termina con un proceso hasta que finaliza el mismo o se bloquea y una vez finalizado o bloqueado comienza con el siguiente que llego. El objetivo de este algoritmo es minimizar al máximo los cambios de contexto. Sabemos que muchos cambios de contexto penalizan el rendimiento del sistema y minimizarlos es mejorar el rendimiento.
Algoritmo SJF(Sortest Job First – Primero el trabajo más corto).
Este algoritmo beneficia los trabajos más cortos y por lo tanto lo que intenta maximizar es el número de trabajos realizados por unidad de tiempo. Por contra, los trabajos más largos se ven penalizados y ralentizados.
Algoritmo SJRF(Sortest Job Remaining First – Primero el trabajo que le quede menos tiempo).
Este algoritmo beneficia los trabajos más cortos o ya iniciados y por lo tanto lo que intenta maximizar es el número de trabajos realizados por unidad de tiempo. Por contra, los trabajos más largos se ven penalizados y ralentizados.
SPN (Shortest Process Next – El siguiente el más corto).
Es parecido al SJF pero permite terminar el trabajo actual (no es expropiativo) para no generar muchos cambios de contexto y maximizar el throughput del sistema.
HRRN (Highest Response Ratio Next – el siguiente el que tenga la tasa de respuesta mayor).
Este algoritmo elegirá como siguiente proceso a ejecutar al que muestre mayor tasa de respuesta.Teniendo en cuenta que la tasa de respuesta se calcula con la siguiente fórmula:
Trespuesta = (Tespera + Tservicio) / Tservicio
Beneficia a los procesos que han esperado mucho.
Algoritmo de elección por prioridades.
En este caso la elección viene ya dada según la prioridad del proceso. Se atenderán primero los procesos con prioridad más alta.
Para ser más equitativo, este sistema puede prever prioridades que vayan cambiando. Las prioridades no tiene por qué ser estáticas sino que pueden ir modificándose aumentando o disminuyendo la prioridad según conveniencia.
Algoritmos con varias colas.
Se pueden utilizar varias colas, otorgando más prioridad a una cola que a otra y dentro de estas colas se puede utilizar otro criterio como FCFS, SJF, Round Robin, etc.
11. Ejemplos de estos algoritmos de planificación.
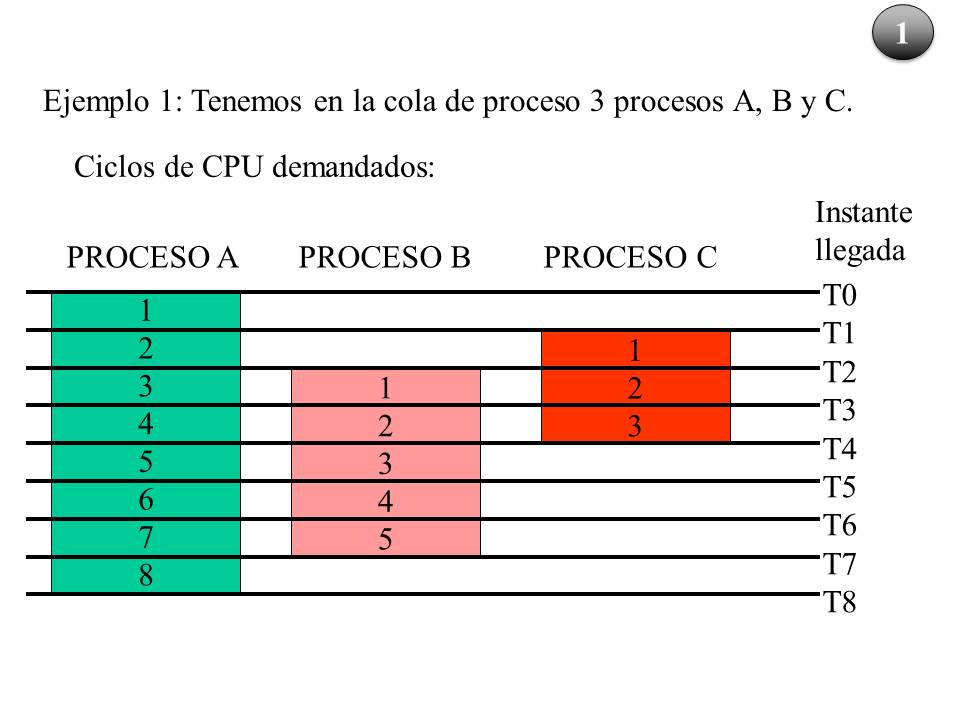
Tenemos tres procesos que llegan al sistema en distintos intervalos de tiempo. En la figura se representan el orden e instante de llegada, así como el número de ciclos demandados. El proceso A demanda 8 ciclos, el proceso B 5 y el proceso C demanda 3 ciclos.
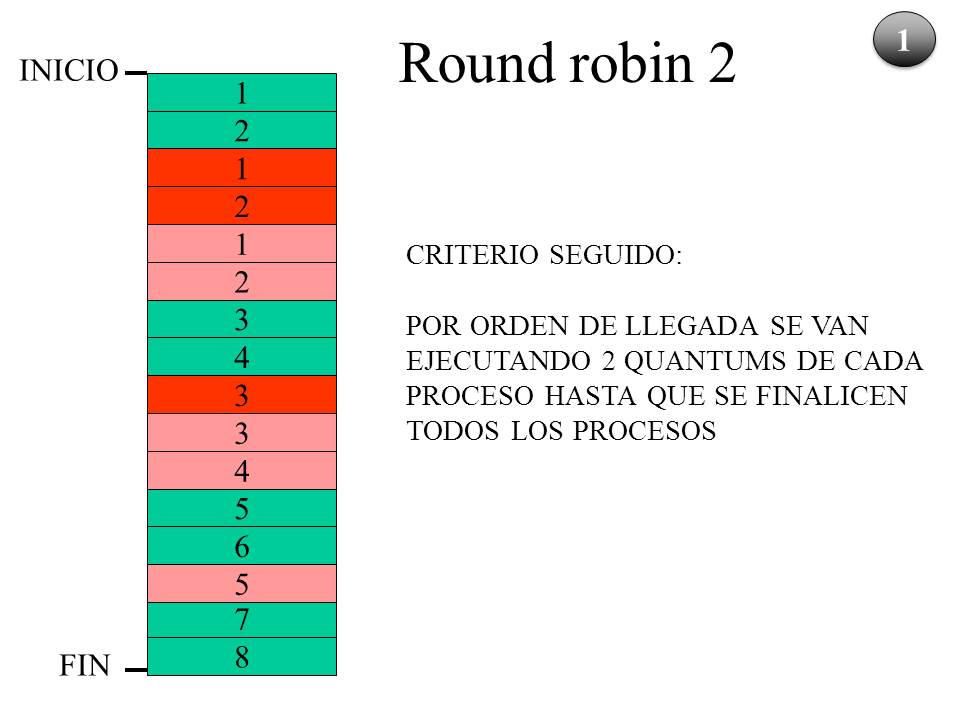
La asignación de la CPU en este caso será atendiendo al criterio Round Robin. Por orden de llegada se van asignando 2 quantums de tiempo a cada proceso, luego se comenzará por el proceso A (verde) seguido por el C (rojo) y por último el B (rosa).
Una vez repartidos 2 quantums a cada proceso se comienza con el primero.
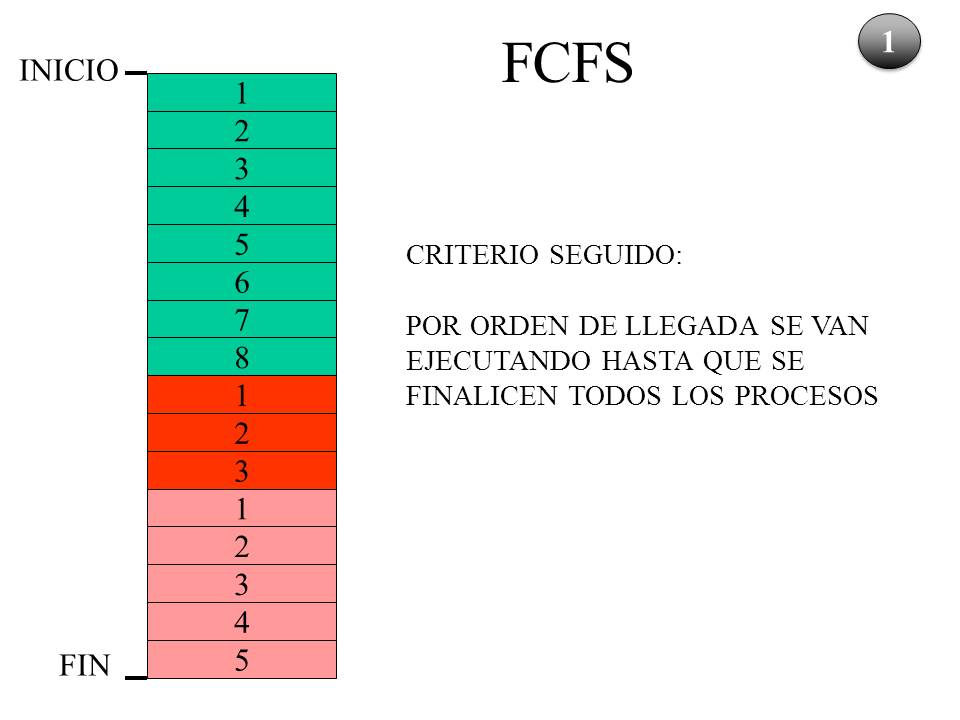
En este caso la asignación de tiempo se realiza siguiendo el criterio FCFS, primero en llegar primero en ser servido. Dado que el orden de llegada ha sido A, C y B, este será el orden en el cual van a ser atendidos los procesos.
12. Ejercicios de algoritmos de planificación.
A continuación se muestran una serie de ejercicios de planificación. Para poder realizar estos ejercicios correctamente deberás tener en cuenta los siguientes términos:
- Tiempo de retorno de un proceso. Es el tiempo que tarda un proceso desde que ingresa a la cola de los preparados hasta que abandona el sistema y el planificador lo marca como finalizado. (minimizar)
- Tiempo de servicio de un proceso. Es lo mismo que el tiempo de retorno. (minimizar)
- Tiempo de espera de un proceso. Es el tiempo que pasa un proceso en la cola de activos (en estado preparado) sin ser atendido por la CPU.(minimizar)
- Tiempo de respuesta de un proceso. Es el tiempo que pasa un proceso desde que ingresa en la cola de activos hasta que es atendido primeramente por la CPU. Muchas veces un valor aislado no da mucha información y lo que se calcula es el tiempo medio de respuesta que ofrece una visión más real.(minimizar)
- Grado utilización de la CPU. Tanto por ciento del tiempo que la CPU está ocupada.(maximizar)
- Productividad de una CPU (también throughput). Número de procesos que se completan por unidad de tiempo.(maximizar)
- Tiempo de retorno o servicio de una serie de procesos. Media del tiempo de retorno de dicha serie de procesos.(minimizar)
- Tiempo de espera de una serie de procesos. Media del tiempo de retorno de dicha serie de procesos.(minimizar)
Una CPU con quanto = 0.25 ms debe planificar la ejecución de varios procesos A , B , C y D que llegan en el siguiente orden.
A. Llega al comienzo.
B. Llega 3 quantos más tarde
C. Llega 3 ms más tarde
D. Llega 4 ms más tarde
Dichos procesos están compuestos de varias ráfagas de CPU y E/S, donde todas las ráfagas de E/S hacen uso del mismo dispositivo de E/S.
Proceso A (CPU 9q, E/S 5q, CPU 5q)
Proceso B (CPU 2q, E/S 3q, CPU 3q)
Proceso C (CPU 3q, E/S 1q, CPU 2q, E/S 1q, CPU 1q)
Proceso D (CPU 2q, E/S 2q, CPU 3q)
a) Utilizando el algoritmo de planificación por turno circular (con quanto = 4), SJF y FCFS, representar el diagrama de Gantt de la evolución de los procesos en el sistema.
b) Definir los siguientes criterios, que nos permitirán analizar la eficiencia de las alternativas calculadas anteriormente:
i. % Utilización de la CPU
ii. Rendimiento
iii. Tiempo de retorno (tiempo de servicio)
iv. Tiempo de espera
v. Tiempo de respuesta
c) ¿Cuál de los algoritmos es más eficiente y por qué?